はじめに
前回までで、MediaPipeの一通りの機能を体験することができました☺️
と、思ったら・・・
2024からソリューションが新しくなり、前回まで書いていたコードは旧ソリューションの方法だったことが判明😖
ということで、新版もやってみることにしました。
MediaPipeの機能
公式HPはこちら。
https://ai.google.dev/edge/mediapipe/solutions/guide?hl=ja
提供されている機能のリストです。
顔や手の検出は、視覚タスクにあります。旧版から大きく変わったのは以下です。
・カメラからの画像を取り込む場合、結果をcallbackで受け取る
・オブジェクト検出するために、機械学習済みファイルを使用する
機械学習済みファイルは、公式HPで配布されています。
ソリューションの置き換え状況も書かれています。
新版のholisticはまだ提供されていないようです。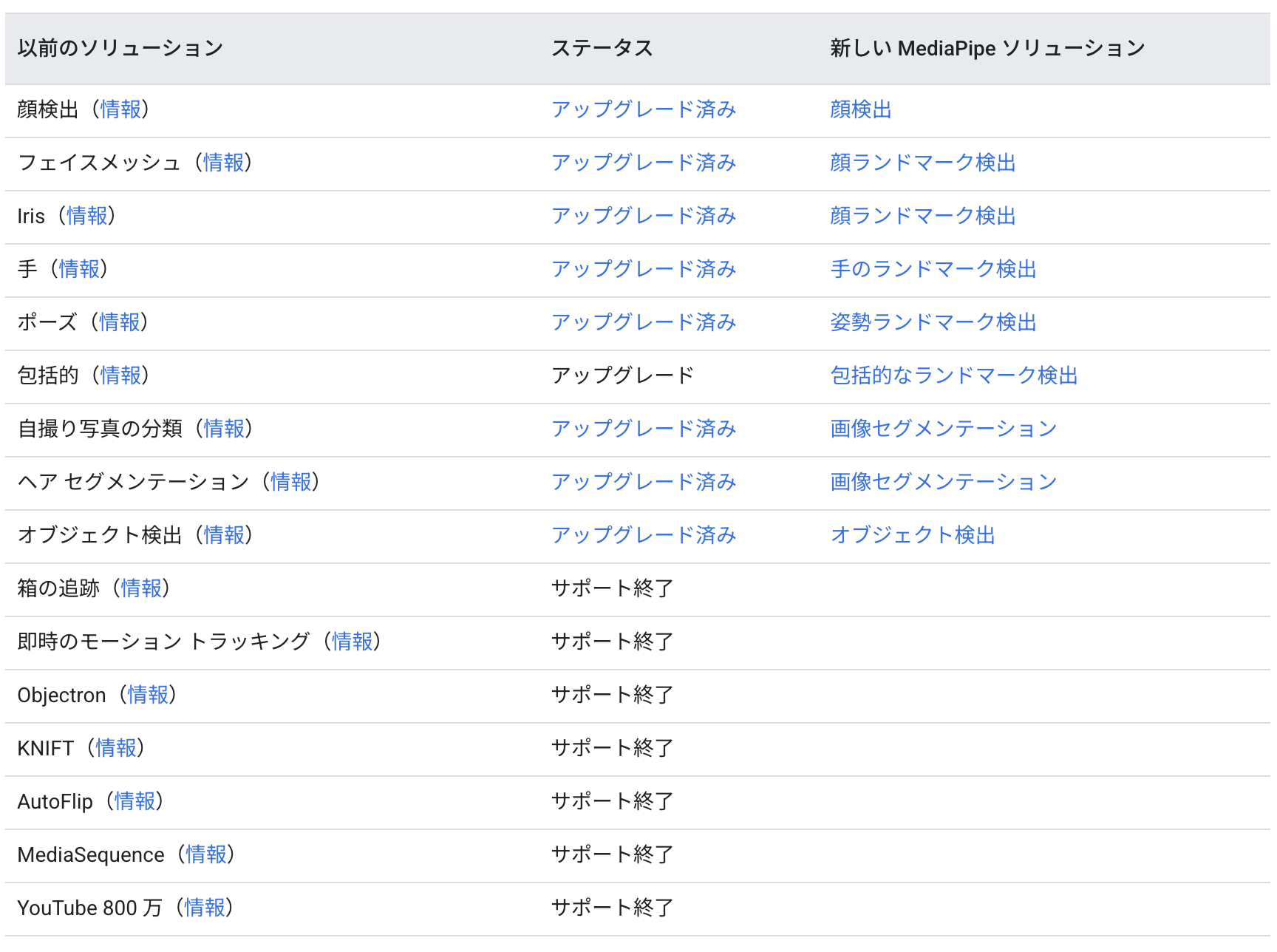
今回は顔と手の検出だけ試してみます。
Face Landmarker
機械学習済みモデルは、このページの一番下で配布されています。
https://ai.google.dev/edge/mediapipe/solutions/vision/face_landmarker/index?hl=ja&_gl=1*1etw4vc*_up*MQ..*_ga*MTM4NjE0MTUxNS4xNzQwNTE1NzYx*_ga_P1DBVKWT6V*MTc0MDUxNTc2MC4xLjAuMTc0MDUxNTgyNS4wLjAuMTc5MDg5NTE3Nw..#models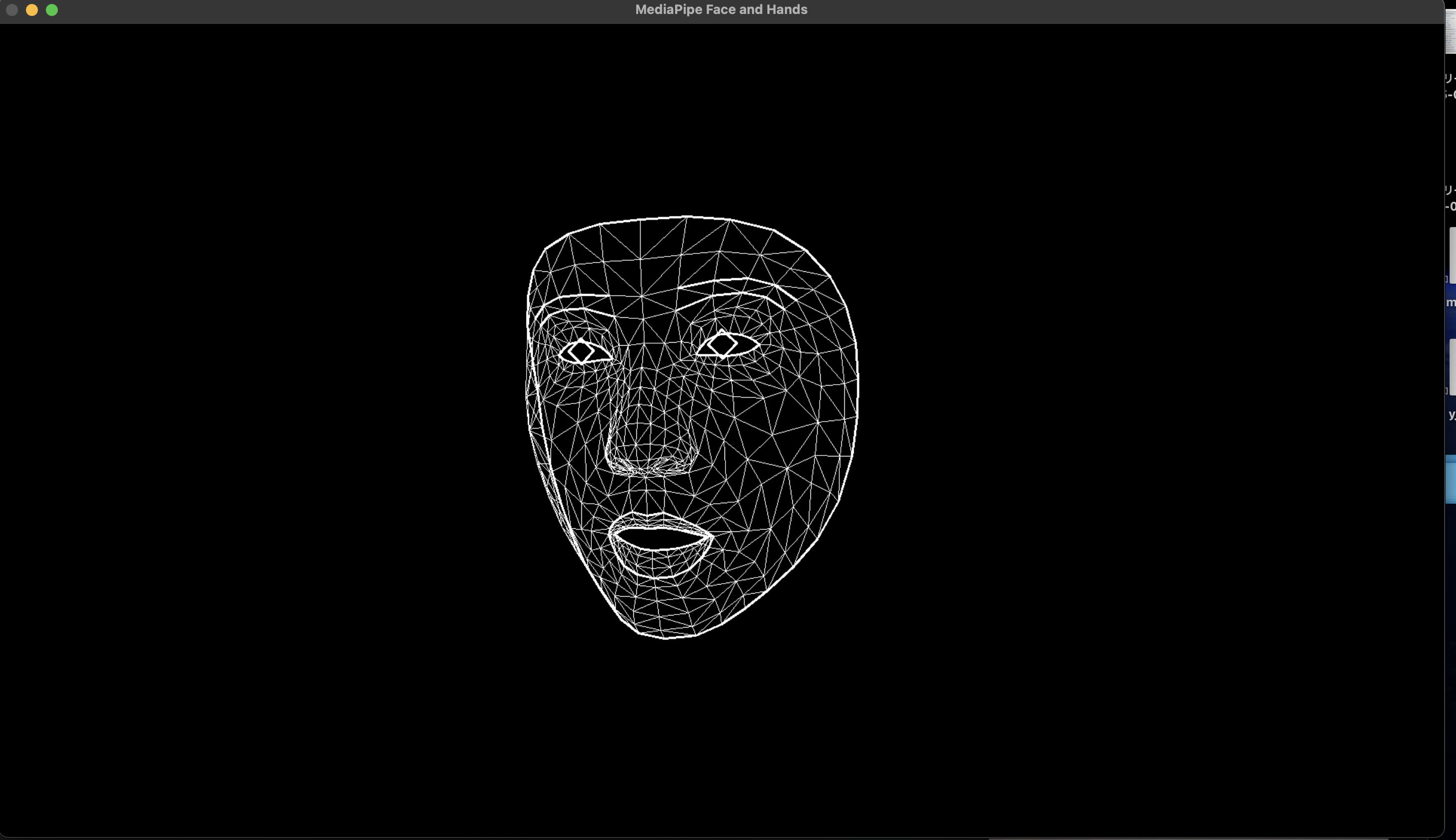
Face Landmarkerサンプルコード
import time
import cv2
import mediapipe as mp
import numpy as np
from mediapipe.framework.formats import landmark_pb2
face_model_path = './face_landmarker.task'
BaseOptions = mp.tasks.BaseOptions
FaceLandmarker = mp.tasks.vision.FaceLandmarker
FaceLandmarkerOptions = mp.tasks.vision.FaceLandmarkerOptions
FaceLandmarkerResult = mp.tasks.vision.FaceLandmarkerResult
VisionRunningMode = mp.tasks.vision.RunningMode
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_face_mesh = mp.solutions.face_mesh
annotated_image_face = None
def draw_landmarks_on_image_face(rgb_image, detection_result):
annotated_image = np.copy(rgb_image)
# 背景を黒にして、ランドマーク画像だけ残す
img_h, img_w, _ = annotated_image.shape
blank = np.zeros((img_h, img_w, 3))
annotated_image = blank
# 顔を認識できなくなるとエラー終了してしまうので、捉えているか判定する
if detection_result.face_landmarks:
face_landmarks_list = detection_result.face_landmarks
# Loop through the detected faces to visualize.
for idx in range(len(face_landmarks_list)):
face_landmarks = face_landmarks_list[idx]
# Draw the face landmarks.
face_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
face_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in face_landmarks
])
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=face_landmarks_proto,
connections=mp_face_mesh.FACEMESH_TESSELATION,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_tesselation_style())
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=face_landmarks_proto,
connections=mp_face_mesh.FACEMESH_CONTOURS,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_contours_style())
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=face_landmarks_proto,
connections=mp_face_mesh.FACEMESH_IRISES,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_iris_connections_style())
return annotated_image
# Create a face landmarker instance with the live stream mode:
def print_result_face(result: FaceLandmarkerResult, output_image: mp.Image, timestamp_ms: int):
# print('face landmarker result: {}'.format(result))
global annotated_image_face
annotated_image_face = draw_landmarks_on_image_face(
output_image.numpy_view(), result
)
options = FaceLandmarkerOptions(
base_options=BaseOptions(model_asset_path=face_model_path),
running_mode=VisionRunningMode.LIVE_STREAM,
num_faces=1,
min_face_detection_confidence=0.5,
min_tracking_confidence=0.5,
result_callback=print_result_face)
face_landmarker = FaceLandmarker.create_from_options(options)
cap = cv2.VideoCapture(0)
# カメラが有効の場合のみ処理する
while cap.isOpened():
# カメラから画像1枚取得
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image)
frame_timestamp_ms = int(time.time() * 1000)
face_landmarker.detect_async(mp_image, frame_timestamp_ms)
# PC画面に画像表示
if annotated_image_face is not None:
annotated_image_face = cv2.flip(annotated_image_face, 1) # ミラー反転する
cv2.imshow('MediaPipe Face and Hands', annotated_image_face)
#終了判定 ESCで終了する
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
コードを見てみましょう。
face_model_path = './face_landmarker.task'
機械学習済みファイルへのパスを書きます。今回はソースファイルと同じフォルダに入れました。
options = FaceLandmarkerOptions(
base_options=BaseOptions(model_asset_path=face_model_path),
running_mode=VisionRunningMode.LIVE_STREAM,
num_faces=1,
min_face_detection_confidence=0.5,
min_tracking_confidence=0.5,
result_callback=print_result_face)
顔ランドマーク検出のオプションを指定します。
RunningModeは3種類あります。
IMAGE:画像入力
VIDEO:動画入力
LIVE_STREAM:カメラなどからの入力データのライブ配信
➡︎この場合、結果はresult_callbackで指定したコールバック関数で受け取る
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image)
frame_timestamp_ms = int(time.time() * 1000)
face_landmarker.detect_async(mp_image, frame_timestamp_ms)
detect_async()で検出処理を開始します。
引数にタイムスタンプを指定する必要があるため、timeで計算しています。
def print_result_face(result: FaceLandmarkerResult, output_image: mp.Image, timestamp_ms: int):
# print('face landmarker result: {}'.format(result))
global annotated_image_face
annotated_image_face = draw_landmarks_on_image_face(
output_image.numpy_view(), result
)
結果を受け取るコールバック関数。
resultに検出したランドマーク情報が入っています。
# 顔を認識できなくなるとエラー終了してしまうので、捉えているか判定する
if detection_result.face_landmarks:
基本的には公式HPのサンプルコードそのものですが、注意すべきはdraw_landmarks_on_image_face()関数の上記部分です。
これがないと、顔が画面外に出たり隠れたりして認識できなくなったとき、エラー終了してしまいます。
Hand Landmarker
機械学習済みモデルは、このページの一番下で配布されています。
https://ai.google.dev/edge/mediapipe/solutions/vision/hand_landmarker/index?hl=ja&_gl=1*1v7xp3d*_up*MQ..*_ga*MTM4NjE0MTUxNS4xNzQwNTE1NzYx*_ga_P1DBVKWT6V*MTc0MDUxNTc2MC4xLjAuMTc0MDUxNTgyNS4wLjAuMTc5MDg5NTE3Nw..#models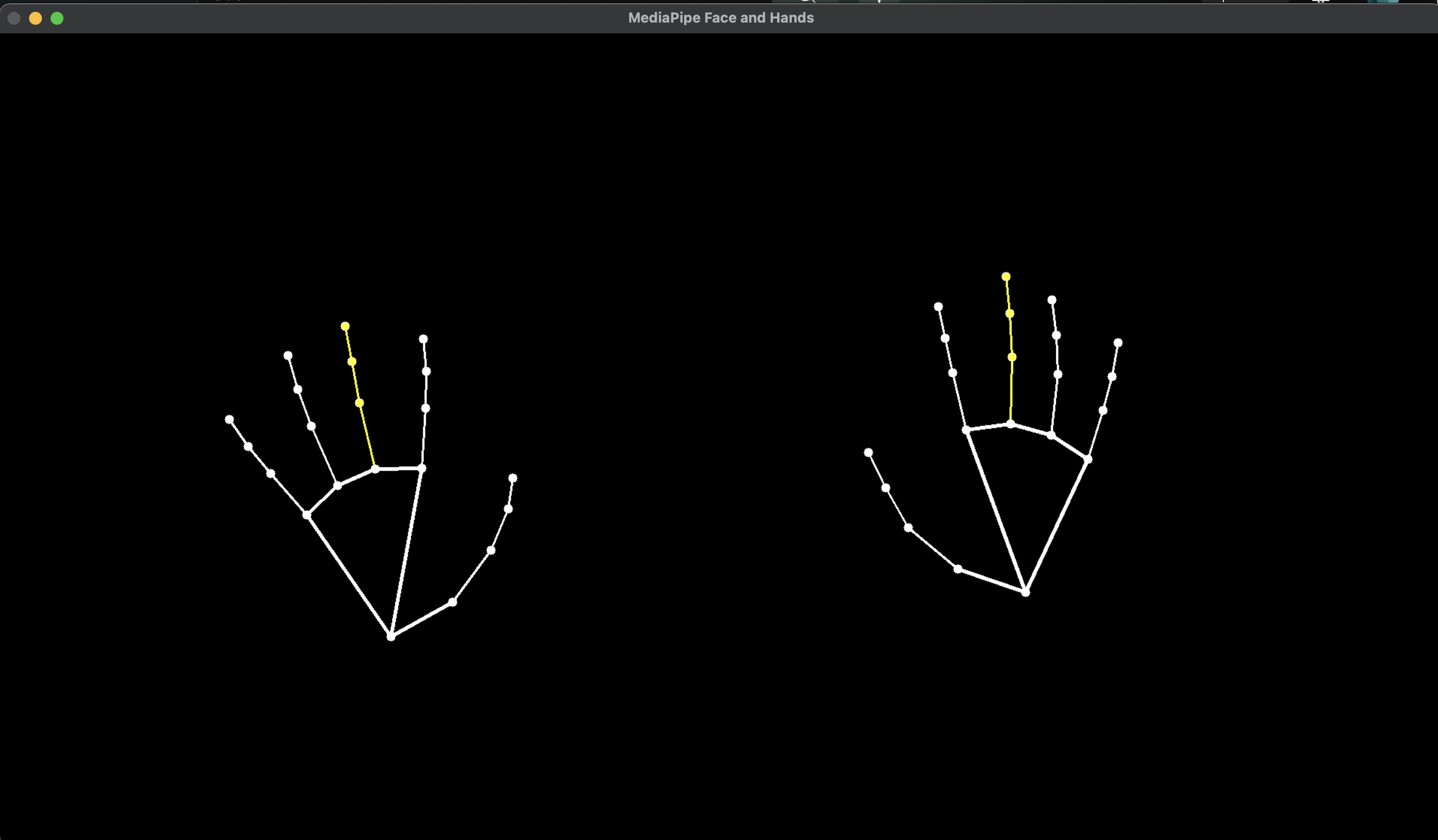
ちゃんと両手を認識してますね。
Hand Landmarkerサンプルコード
import time
import cv2
import mediapipe as mp
import numpy as np
from mediapipe.framework.formats import landmark_pb2
hands_model_path = './hand_landmarker.task'
BaseOptions = mp.tasks.BaseOptions
HandLandmarker = mp.tasks.vision.HandLandmarker
HandLandmarkerOptions = mp.tasks.vision.HandLandmarkerOptions
HandLandmarkerResult = mp.tasks.vision.HandLandmarkerResult
VisionRunningMode = mp.tasks.vision.RunningMode
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_hands = mp.solutions.hands
annotated_image_hands = None
MARGIN = 10 # pixels
FONT_SIZE = 1
FONT_THICKNESS = 1
HANDEDNESS_TEXT_COLOR = (88, 205, 54) # vibrant green
def draw_landmarks_on_image_hands(rgb_image, detection_result):
# print('hand landmarker result: {}'.format(detection_result))
annotated_image = np.copy(rgb_image)
# 背景を黒にして、ランドマーク画像だけ残す
img_h, img_w, _ = annotated_image.shape
blank = np.zeros((img_h, img_w, 3))
annotated_image = blank
# 手を認識できなくなるとエラー終了してしまうので、捉えているか判定する
if detection_result.hand_landmarks:
hand_landmarks_list = detection_result.hand_landmarks
handedness_list = detection_result.handedness
# Loop through the detected hands to visualize.
for idx in range(len(hand_landmarks_list)):
hand_landmarks = hand_landmarks_list[idx]
handedness = handedness_list[idx]
# Draw the hand landmarks.
hand_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
hand_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in hand_landmarks
])
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=hand_landmarks_proto,
connections=mp_hands.HAND_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_hand_landmarks_style(),
connection_drawing_spec=mp_drawing_styles.get_default_hand_connections_style())
# Get the top left corner of the detected hand's bounding box.
height, width, _ = annotated_image.shape
x_coordinates = [landmark.x for landmark in hand_landmarks]
y_coordinates = [landmark.y for landmark in hand_landmarks]
text_x = int(min(x_coordinates) * width)
text_y = int(min(y_coordinates) * height) - MARGIN
# Draw handedness (left or right hand) on the image.
# cv2.putText(annotated_image, f"{handedness[0].category_name}",
# (text_x, text_y), cv2.FONT_HERSHEY_DUPLEX,
# FONT_SIZE, HANDEDNESS_TEXT_COLOR, FONT_THICKNESS, cv2.LINE_AA)
return annotated_image
# Create a hand landmarker instance with the live stream mode:
def print_result_hands(result: HandLandmarkerResult, output_image: mp.Image, timestamp_ms: int):
# print('face landmarker result: {}'.format(result))
global annotated_image_hands
annotated_image_hands = draw_landmarks_on_image_hands(
output_image.numpy_view(), result
)
hands_options = HandLandmarkerOptions(
base_options=BaseOptions(model_asset_path=hands_model_path),
running_mode=VisionRunningMode.LIVE_STREAM,
num_hands=2,
min_hand_detection_confidence=0.5,
min_tracking_confidence=0.5,
result_callback=print_result_hands)
hands_landmarker = HandLandmarker.create_from_options(hands_options)
cap = cv2.VideoCapture(0)
# カメラが有効の場合のみ処理する
while cap.isOpened():
# カメラから画像1枚取得
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image)
frame_timestamp_ms = int(time.time() * 1000)
hands_landmarker.detect_async(mp_image, frame_timestamp_ms)
# PC画面に画像表示
if annotated_image_hands is not None:
annotated_image_hands = cv2.flip(annotated_image_hands, 1) # ミラー反転する
cv2.imshow('MediaPipe Face and Hands', annotated_image_hands)
#終了判定 ESCで終了する
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
基本的な書き方はFace Landmarkerと同様です。
# Draw handedness (left or right hand) on the image.
# cv2.putText(annotated_image, f"{handedness[0].category_name}",
# (text_x, text_y), cv2.FONT_HERSHEY_DUPLEX,
# FONT_SIZE, HANDEDNESS_TEXT_COLOR, FONT_THICKNESS, cv2.LINE_AA)
ここを有効にすると、手の少し上あたりに、どちらの手なのかの文字列を表示できます。
最終的にミラー反転してしまいますが😅
ミラー反転の処理順を調整すれば、うまく表示できると思います。
# 手を認識できなくなるとエラー終了してしまうので、捉えているか判定する
if detection_result.hand_landmarks:
こちらもFace Landmarkerと同じ注意点です。
これがないと、手が画面外に出たり隠れたりして認識できなくなったとき、エラー終了してしまいます。
Face + Hands
顔検出と手検出の組み合わせです。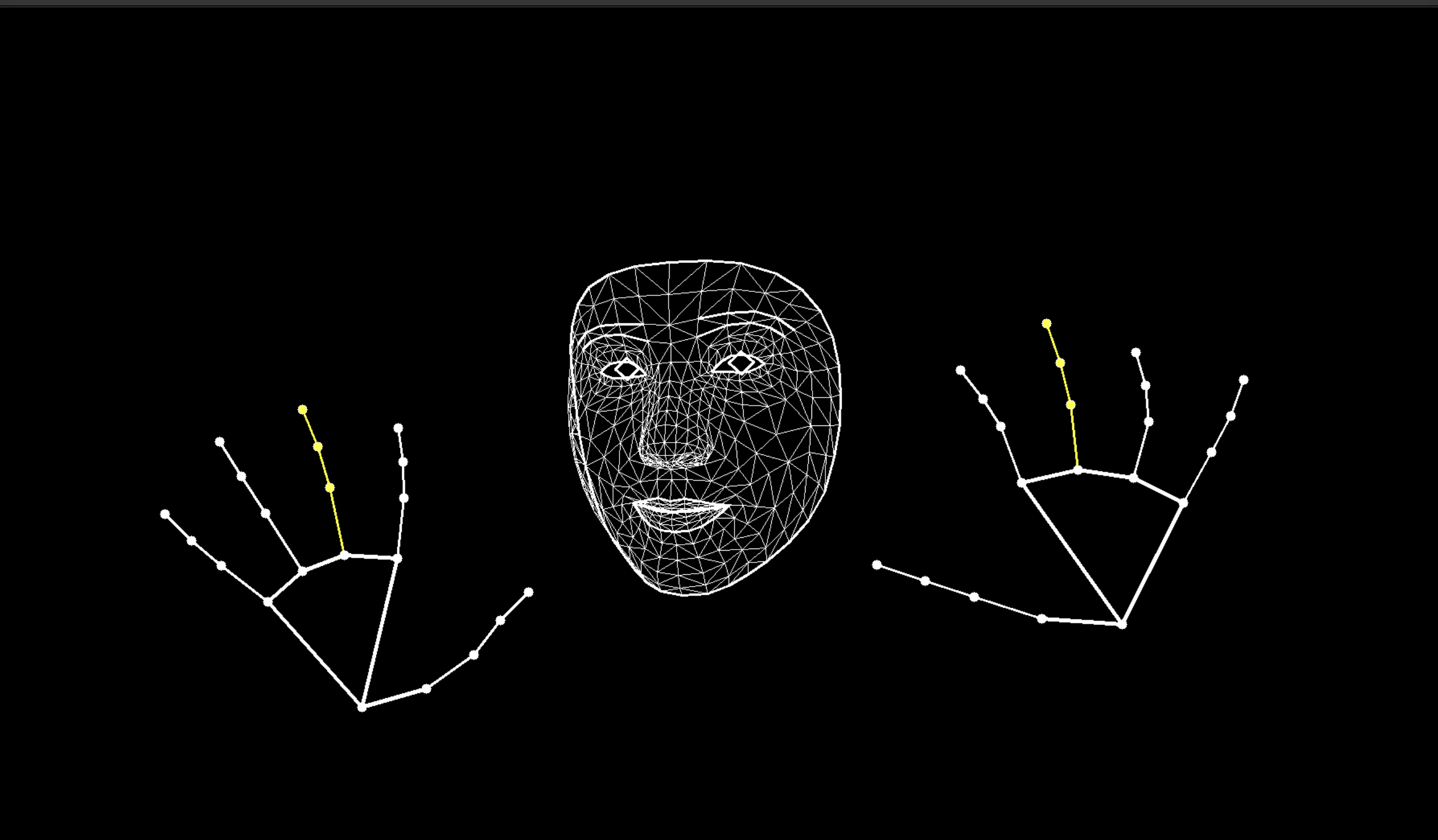
Face + Hands サンプルコード
import time
import cv2
import mediapipe as mp
import numpy as np
from mediapipe.framework.formats import landmark_pb2
face_model_path = './face_landmarker.task'
hands_model_path = './hand_landmarker.task'
BaseOptions = mp.tasks.BaseOptions
FaceLandmarker = mp.tasks.vision.FaceLandmarker
FaceLandmarkerOptions = mp.tasks.vision.FaceLandmarkerOptions
FaceLandmarkerResult = mp.tasks.vision.FaceLandmarkerResult
HandLandmarker = mp.tasks.vision.HandLandmarker
HandLandmarkerOptions = mp.tasks.vision.HandLandmarkerOptions
HandLandmarkerResult = mp.tasks.vision.HandLandmarkerResult
VisionRunningMode = mp.tasks.vision.RunningMode
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_face_mesh = mp.solutions.face_mesh
mp_hands = mp.solutions.hands
annotated_image_face = None
annotated_image_hands = None
def draw_landmarks_on_image_face(rgb_image, detection_result):
annotated_image = np.copy(rgb_image)
# 背景を黒にして、ランドマーク画像だけ残す
img_h, img_w, _ = annotated_image.shape
blank = np.zeros((img_h, img_w, 3))
annotated_image = blank
# 顔を認識できなくなるとエラー終了してしまうので、捉えているか判定する
if detection_result.face_landmarks:
face_landmarks_list = detection_result.face_landmarks
# Loop through the detected faces to visualize.
for idx in range(len(face_landmarks_list)):
face_landmarks = face_landmarks_list[idx]
# Draw the face landmarks.
face_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
face_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in face_landmarks
])
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=face_landmarks_proto,
connections=mp_face_mesh.FACEMESH_TESSELATION,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_tesselation_style())
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=face_landmarks_proto,
connections=mp_face_mesh.FACEMESH_CONTOURS,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_contours_style())
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=face_landmarks_proto,
connections=mp_face_mesh.FACEMESH_IRISES,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_iris_connections_style())
return annotated_image
def draw_landmarks_on_image_hands(rgb_image, detection_result):
# print('hand landmarker result: {}'.format(detection_result))
annotated_image = np.copy(rgb_image)
# 背景を黒にして、ランドマーク画像だけ残す
img_h, img_w, _ = annotated_image.shape
blank = np.zeros((img_h, img_w, 3))
annotated_image = blank
# 手を認識できなくなるとエラー終了してしまうので、捉えているか判定する
if detection_result.hand_landmarks:
hand_landmarks_list = detection_result.hand_landmarks
handedness_list = detection_result.handedness
# Loop through the detected hands to visualize.
for idx in range(len(hand_landmarks_list)):
hand_landmarks = hand_landmarks_list[idx]
handedness = handedness_list[idx]
# Draw the hand landmarks.
hand_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
hand_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in hand_landmarks
])
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=hand_landmarks_proto,
connections=mp_hands.HAND_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_hand_landmarks_style(),
connection_drawing_spec=mp_drawing_styles.get_default_hand_connections_style())
return annotated_image
# Create a face landmarker instance with the live stream mode:
def print_result_face(result: FaceLandmarkerResult, output_image: mp.Image, timestamp_ms: int):
# print('face landmarker result: {}'.format(result))
global annotated_image_face
annotated_image_face = draw_landmarks_on_image_face(
output_image.numpy_view(), result
)
# Create a hand landmarker instance with the live stream mode:
def print_result_hands(result: HandLandmarkerResult, output_image: mp.Image, timestamp_ms: int):
# print('face landmarker result: {}'.format(result))
global annotated_image_hands
annotated_image_hands = draw_landmarks_on_image_hands(
output_image.numpy_view(), result
)
face_options = FaceLandmarkerOptions(
base_options=BaseOptions(model_asset_path=face_model_path),
running_mode=VisionRunningMode.LIVE_STREAM,
num_faces=1,
min_face_detection_confidence=0.5,
min_tracking_confidence=0.5,
result_callback=print_result_face)
hands_options = HandLandmarkerOptions(
base_options=BaseOptions(model_asset_path=hands_model_path),
running_mode=VisionRunningMode.LIVE_STREAM,
num_hands=2,
min_hand_detection_confidence=0.5,
min_tracking_confidence=0.5,
result_callback=print_result_hands)
face_landmarker = FaceLandmarker.create_from_options(face_options)
hands_landmarker = HandLandmarker.create_from_options(hands_options)
cap = cv2.VideoCapture(0)
# カメラが有効の場合のみ処理する
while cap.isOpened():
# カメラから画像1枚取得
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image)
frame_timestamp_ms = int(time.time() * 1000)
face_landmarker.detect_async(mp_image, frame_timestamp_ms)
hands_landmarker.detect_async(mp_image, frame_timestamp_ms)
# PC画面に画像表示
if (annotated_image_face is not None) and (annotated_image_hands is not None):
# フェイストラッキング結果とハンドトラッキング結果の画像を合成
annotated_image = cv2.addWeighted(src1=annotated_image_face, alpha=0.5, src2=annotated_image_hands, beta=0.5, gamma=0)
annotated_image = cv2.flip(annotated_image, 1) # ミラー反転する
cv2.imshow('MediaPipe Face and Hands', annotated_image)
#終了判定 ESCで終了する
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
単体の検出と違うのは、画面表示する直前に2つの画像を合成していることです。
FPSが上がらない
FPSのうまい計測方法が思いつかなかったので計測してませんが、旧版と比較して重くなった気がします。
コールバックを取りこぼしている可能性もあるので、今後検証を進めようと思っています。
取りこぼしを解消するには、一般的にはリングバッファとか使うんですが、今回扱うデータのサイズが大きめなんですよね・・・考え中🤔
さいごに
新ソリューションのMediaPipeを使ってみました。
eightとしては顔と手をトラッキングできれば良いので、その組み合わせでいこうと思っていますが、今後提供されるであろうholisticでも同じことができるなら、そちらに変更するかもしれません。
パフォーマンス次第ですね。
それでは、今回はここまで。
ありがとうございました☺️


コメント