はじめに
前回までで、MediaPipeの基本的な使い方がわかりました☺️
最終的にはUnity上で動かすことを目指しているので、今回はUnityに渡すところを作っていきます。
UnityとMediaPipeの連携
最終的にはUnityでアバターを動かします。そのためにはMediaPipeで検出した情報をUnityへ通知する必要があります。
これには2通りの方法があります。
・MediaPipeUnityPluginを使用する
・内部通信で渡す
他に、Pythonコードをライブラリ化してUnityから呼び出すこともできるかもしれません。
方法はよくわかっていません🤔
MediaPipeUnityPlugin
C++のMediaPipeを、Unity上で使えるようにしたプラグインです。
今から実装するのであれば、こちらを使用したほうが簡単かもしれません。
pluginはgitで公開されていて、導入方法なども書かれているようです。
https://github.com/homuler/MediaPipeUnityPlugin
内部通信(UDP)
異なるソフトウェア同士でデータをやりとりする場合に、内部通信を使用します。
内部通信にはTCPかUDPかの選択肢がありますが、トラッキングはリアルタイム性が重要であるため、UDPを使用します。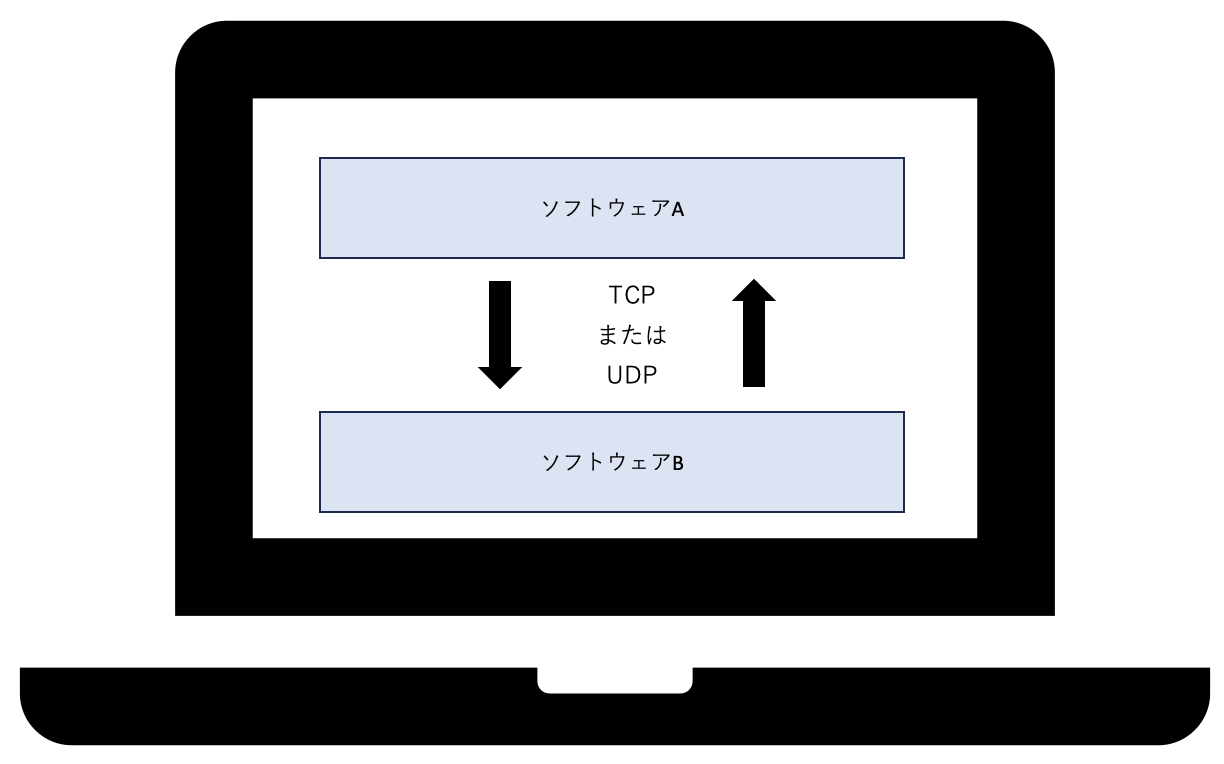
MediaPipeUnityPluginは、当然ながらUnity専用となります。
自分で通信実装したほうが、対Unity以外にもいろいろ応用が効きそうなので、今回は内部通信を採用することにしました。詰まったらMediaPipeUnityPluginも試してみます。
・・・本当はもっとスマートな方法のほうが良いんですが、やってみたかったのです😌
もしリアルタイム性などに問題がありそうなら、別の策を考えます。
顔+両手トラッキング UDP送信対応
ソースコード
ひとまずUDP送信側のお試し版完成ということで、こちらに貼ります。
まだまだ検討の余地はあります。
UDP送信サンプルコード(Python)
import time
import cv2
import mediapipe as mp
import numpy as np
from socket import socket, AF_INET, SOCK_DGRAM
import json
HOST = ''
PORT = 5000
ADDRESS = "127.0.0.1"
face_model_path = './face_landmarker.task'
hands_model_path = './hand_landmarker.task'
BaseOptions = mp.tasks.BaseOptions
FaceLandmarker = mp.tasks.vision.FaceLandmarker
FaceLandmarkerOptions = mp.tasks.vision.FaceLandmarkerOptions
FaceLandmarkerResult = mp.tasks.vision.FaceLandmarkerResult
HandLandmarker = mp.tasks.vision.HandLandmarker
HandLandmarkerOptions = mp.tasks.vision.HandLandmarkerOptions
HandLandmarkerResult = mp.tasks.vision.HandLandmarkerResult
VisionRunningMode = mp.tasks.vision.RunningMode
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_face_mesh = mp.solutions.face_mesh
mp_hands = mp.solutions.hands
mp_face_drawing_spec = mp_drawing.DrawingSpec(thickness=1, circle_radius=1, color=(0, 0, 255))
face_blendshapes_json = None
right_hand_world_landmarks_json = None
left_hand_world_landmarks_json = None
def get_face_blendshapes_json(detection_result):
face_json = None
face_json_tmp = {}
face_data = []
# 顔を認識できなくなるとエラー終了してしまうので、捉えているか判定する
if detection_result.face_blendshapes:
face_blendshapes_list = detection_result.face_blendshapes
#検出する顔は1つであることが前提
for face_bs in face_blendshapes_list[0]:
face_data.append(face_bs.score) # 配列face_dataにscoreを追加する
face_json_tmp['face'] = face_data # キー'face'に配列face_dataを割り当て jsonへの変換準備完了
face_json = json.dumps(face_json_tmp) #jsonデータに変換する
return face_json
def get_hands_world_landmarks_json(detection_result):
right_hand_json = None
left_hand_json = None
right_hand_json_tmp = {}
left_hand_json_tmp = {}
# 手を認識できなくなるとエラー終了してしまうので、捉えているか判定する
if detection_result.hand_world_landmarks:
hand_landmarks_list = detection_result.hand_world_landmarks
handedness_list = detection_result.handedness
# Loop through the detected hands to visualize.
for idx in range(len(hand_landmarks_list)):
hand_landmarks = hand_landmarks_list[idx]
handedness = handedness_list[idx]
if handedness[0].category_name == "Right":
right_hand_data = []
for landmark in hand_landmarks:
right_hand_data_xyz = []
right_hand_data_xyz.append(landmark.x)
right_hand_data_xyz.append(landmark.y)
right_hand_data_xyz.append(landmark.z)
right_hand_data.append(right_hand_data_xyz)
right_hand_json_tmp['hand_right'] = right_hand_data # キー'hand_right'に配列right_hand_dataを割り当て jsonへの変換準備完了
right_hand_json = json.dumps(right_hand_json_tmp) #jsonデータに変換する
elif handedness[0].category_name == "Left":
left_hand_data = []
for landmark in hand_landmarks:
left_hand_data_xyz = []
left_hand_data_xyz.append(landmark.x)
left_hand_data_xyz.append(landmark.y)
left_hand_data_xyz.append(landmark.z)
left_hand_data.append(left_hand_data_xyz)
left_hand_json_tmp['hand_left'] = left_hand_data # キー'hand_left'に配列left_hand_dataを割り当て jsonへの変換準備完了
left_hand_json = json.dumps(left_hand_json_tmp) #jsonデータに変換する
else:
pass
return right_hand_json, left_hand_json
# Create a face landmarker instance with the live stream mode:
def print_result_face(result: FaceLandmarkerResult, output_image: mp.Image, timestamp_ms: int):
global face_blendshapes_json
# 顔はblendshapeデータをjson形式にするだけ
face_blendshapes_json = get_face_blendshapes_json(
result
)
# Create a hand landmarker instance with the live stream mode:
def print_result_hands(result: HandLandmarkerResult, output_image: mp.Image, timestamp_ms: int):
global right_hand_world_landmarks_json, left_hand_world_landmarks_json
# 両手はworld landmarkデータをjson形式にするだけ
right_hand_world_landmarks_json, left_hand_world_landmarks_json = get_hands_world_landmarks_json(
result
)
s = socket(AF_INET, SOCK_DGRAM)
face_options = FaceLandmarkerOptions(
base_options=BaseOptions(model_asset_path=face_model_path),
running_mode=VisionRunningMode.LIVE_STREAM,
num_faces=1,
min_face_detection_confidence=0.5,
min_tracking_confidence=0.5,
output_face_blendshapes=True,
result_callback=print_result_face)
hands_options = HandLandmarkerOptions(
base_options=BaseOptions(model_asset_path=hands_model_path),
running_mode=VisionRunningMode.LIVE_STREAM,
num_hands=2,
min_hand_detection_confidence=0.2,
min_tracking_confidence=0.2,
result_callback=print_result_hands)
face_landmarker = FaceLandmarker.create_from_options(face_options)
hands_landmarker = HandLandmarker.create_from_options(hands_options)
cap = cv2.VideoCapture(0)
# カメラが有効の場合のみ処理する
while cap.isOpened():
# カメラから画像1枚取得
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image)
frame_timestamp_ms = int(time.time() * 1000)
face_landmarker.detect_async(mp_image, frame_timestamp_ms)
hands_landmarker.detect_async(mp_image, frame_timestamp_ms)
# 黒画表示
img_h = 100
img_w = 200
blank = np.zeros((img_h, img_w, 3))
cv2.imshow('MediaPipe Send UDP', blank)
# faceの更新データがあれば送信する
if (face_blendshapes_json is not None):
s.sendto(face_blendshapes_json.encode('utf-8'), (ADDRESS, PORT))
face_blendshapes_json = None
# right_handの更新データがあれば送信する
if (right_hand_world_landmarks_json is not None):
s.sendto(right_hand_world_landmarks_json.encode('utf-8'), (ADDRESS, PORT))
right_hand_world_landmarks_json = None
# left_handの更新データがあれば送信する
if (left_hand_world_landmarks_json is not None):
s.sendto(left_hand_world_landmarks_json.encode('utf-8'), (ADDRESS, PORT))
left_hand_world_landmarks_json = None
#終了判定 ESCで終了する
if cv2.waitKey(5) & 0xFF == 27:
break
s.close()
cap.release()
VSCodeで実行すると、小さい黒画のウインドウが起動します。この画面でESCキーを押すと終了します。
テスト用として、以下のような受信側の処理を、VSCodeではなくターミナルで起動すると、UDP送信されたデータを受信して表示することができます。
UDP受信サンプルコード(Python)
from socket import *
import json
import numpy as np
import cv2
## UDP受信クラス
class udprecv():
def __init__(self):
SrcIP = "127.0.0.1" # 受信元IP
SrcPort = 5000 # 受信元ポート番号
self.SrcAddr = (SrcIP, SrcPort) # アドレスをtupleに格納
self.BUFSIZE = 65534 # バッファサイズ指定
self.udpServSock = socket(AF_INET, SOCK_DGRAM) # ソケット作成
self.udpServSock.bind(self.SrcAddr) # 受信元アドレスでバインド
def recv(self):
while True: # 常に受信待ち
data, addr = self.udpServSock.recvfrom(self.BUFSIZE)
rcvdata = json.loads(data.decode())
# 受信データの中にキー'face'があれば表示
if 'face' in rcvdata:
print("face : ", rcvdata['face'])
# 受信データの中にキー'hand_right'があれば表示
if 'hand_right' in rcvdata:
print("hand_right : ", rcvdata['hand_right'])
# 受信データの中にキー'hand_left'があれば表示
if 'hand_left' in rcvdata:
print("hand_left : ", rcvdata['hand_left'])
# 背景を黒にして、ランドマーク画像だけ残す
img_h = 100
img_w = 200
blank = np.zeros((img_h, img_w, 3))
cv2.imshow('MediaPipe Rcv UDP', blank)
#終了判定 ESCで終了する
if cv2.waitKey(5) & 0xFF == 27:
break
udp = udprecv() # クラス呼び出し
udp.recv() # 関数実行
こちらも小さい黒画のウインドウが起動します。この画面でESCキーを押すと終了します。
ターミナルにはこんな感じで表示されます。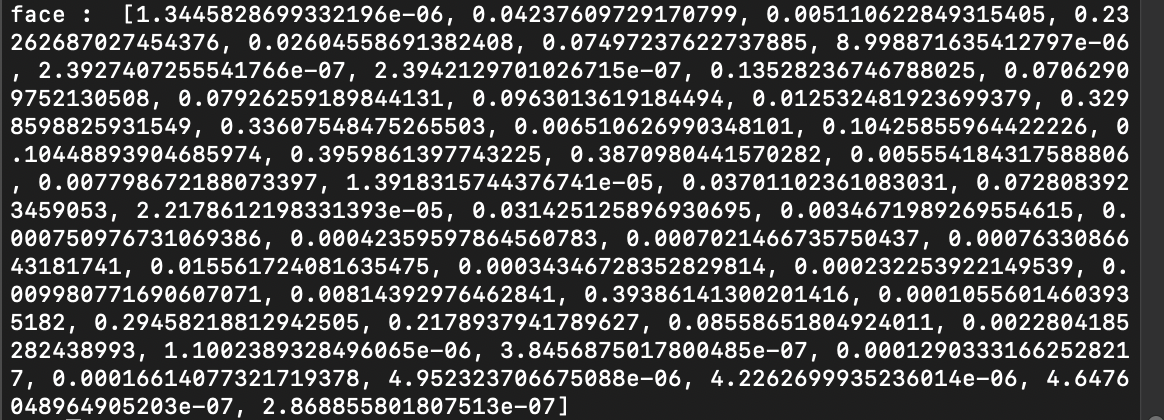
それでは、送信側のコードを順番に見ていきましょう。
Main処理
s = socket(AF_INET, SOCK_DGRAM)
UDP送信のためのソケットを作成します。
UDP使用時はSOCK_DGRAM、TCP使用時はSOCK_STREAMを指定します。
face_options = FaceLandmarkerOptions(
base_options=BaseOptions(model_asset_path=face_model_path),
running_mode=VisionRunningMode.LIVE_STREAM,
num_faces=1,
min_face_detection_confidence=0.5,
min_tracking_confidence=0.5,
output_face_blendshapes=True,
result_callback=print_result_face)
顔検出のオプション指定です。
「output_face_blendshapes=True」を追加しました。
モデルを動かすためには、一般的には「ボーン」と呼ばれる骨格のようなものを、モデルの動かしたい位置に設定します。ブレンドシェイプは、ボーンを設定せず、顔の頂点座標を動かすことで表情を作るときに使用します。
face_landmarker.detect_async(mp_image, frame_timestamp_ms)
hands_landmarker.detect_async(mp_image, frame_timestamp_ms)
ここは前回と同じですね。顔と手のランドマーク検出を開始します。
# 黒画表示
img_h = 100
img_w = 200
blank = np.zeros((img_h, img_w, 3))
cv2.imshow('MediaPipe Send UDP', blank)
背景を黒画にする処理はコールバック処理内にありましたが、ランドマークを画像に描画する必要はなくなったため、ここに移動しました。現状何も表示しないので、画面サイズは小さくしています。
# faceの更新データがあれば送信する
if (face_blendshapes_json is not None):
s.sendto(face_blendshapes_json.encode('utf-8'), (ADDRESS, PORT))
face_blendshapes_json = None
# right_handの更新データがあれば送信する
if (right_hand_world_landmarks_json is not None):
s.sendto(right_hand_world_landmarks_json.encode('utf-8'), (ADDRESS, PORT))
right_hand_world_landmarks_json = None
# left_handの更新データがあれば送信する
if (left_hand_world_landmarks_json is not None):
s.sendto(left_hand_world_landmarks_json.encode('utf-8'), (ADDRESS, PORT))
left_hand_world_landmarks_json = None
顔と両手の送信データをJSON形式にした変数を用意しておき、それをsendto()でUDP送信します。
手は左右で分離しましたが、送信サイズを大きくしすぎないためです。手のランドマークは片手で21点分、それぞれx・y・zの座標を持っています。
更新情報がなければ送信しても仕方ないので、送信するかどうかの判定を加えています。
コールバック関数
・・・
# Create a face landmarker instance with the live stream mode:
def print_result_face(result: FaceLandmarkerResult, output_image: mp.Image, timestamp_ms: int):
global face_blendshapes_json
# 顔はblendshapeデータをjson形式にするだけ
face_blendshapes_json = get_face_blendshapes_json(
result
)
・・・
# Create a hand landmarker instance with the live stream mode:
def print_result_hands(result: HandLandmarkerResult, output_image: mp.Image, timestamp_ms: int):
global right_hand_world_landmarks_json, left_hand_world_landmarks_json
# 両手はworld landmarkデータをjson形式にするだけ
right_hand_world_landmarks_json, left_hand_world_landmarks_json = get_hands_world_landmarks_json(
result
)
・・・
画像にランドマーク情報を描画する関数のかわりに、UDP送信用のJSONデータ作成関数をコールするようにしました。
画像は使用しないので、検出したランドマーク情報やblendshapeだけ渡しています。
顔のblendshapeをJSON形式にする
get_face_blendshapes_json(detection_result)
face_json = None
face_json_tmp = {}
face_data = []
内部変数を初期化します。
face_jsonは、最終的にJSON形式に変換したデータ(戻り値)を格納するのに使用します。
face_json_tmpは辞書型、face_dataはlist型とします。
#検出する顔は1つであることが前提
for face_bs in face_blendshapes_list[0]:
face_data.append(face_bs.score) # 配列face_dataにscoreを追加する
face_blendshapes_listには、検出した顔がlist型で格納されています。顔1つだけなら[0]固定で問題ないです。
list型のface_dataに対して、blendshapeのデータを要素として追加していきます。
blendshapeは以下の並びになっているようなので、データの並びもこの前提とします。
0 : _neutral
1 : browDownLeft
2 : browDownRight
3 : browInnerUp
4 : browOuterUpLeft
5 : browOuterUpRight
6 : cheekPuff
7 : cheekSquintLeft
8 : cheekSquintRight
9 : eyeBlinkLeft
10 : eyeBlinkRight
11 : eyeLookDownLeft
12 : eyeLookDownRight
13 : eyeLookInLeft
14 : eyeLookInRight
15 : eyeLookOutLeft
16 : eyeLookOutRight
17 : eyeLookUpLeft
18 : eyeLookUpRight
19 : eyeSquintLeft
20 : eyeSquintRight
21 : eyeWideLeft
22 : eyeWideRight
23 : jawForward
24 : jawLeft
25 : jawOpen
26 : jawRight
27 : mouthClose
28 : mouthDimpleLeft
29 : mouthDimpleRight
30 : mouthFrownLeft
31 : mouthFrownRight
32 : mouthFunnel
33 : mouthLeft
34 : mouthLowerDownLeft
35 : mouthLowerDownRight
36 : mouthPressLeft
37 : mouthPressRight
38 : mouthPucker
39 : mouthRight
40 : mouthRollLower
41 : mouthRollUpper
42 : mouthShrugLower
43 : mouthShrugUpper
44 : mouthSmileLeft
45 : mouthSmileRight
46 : mouthStretchLeft
47 : mouthStretchRight
48 : mouthUpperUpLeft
49 : mouthUpperUpRight
50 : noseSneerLeft
51 : noseSneerRight
face_json_tmp['face'] = face_data # キー'face'に配列face_dataを割り当て jsonへの変換準備完了
face_json = json.dumps(face_json_tmp) #jsonデータに変換する
辞書型のface_json_tmpのキー’face’に対する値として、face_dataを格納します。
キー’face’を設定するのは、UDP受信側で何のデータなのかを判別するためです。
json_dumps()で、辞書型をJSON形式に変換できます。
手のワールド座標をJSON形式にする
get_hands_world_landmarks_json(detection_result)
right_hand_json = None
left_hand_json = None
right_hand_json_tmp = {}
left_hand_json_tmp = {}
内部変数を初期化します。
right_hand_json/left_hand_jsonは、最終的にJSON形式データを格納するために使用します。
right_hand_json_tmp/left_hand_json_tmpは、JSON形式変換前までをまとめるもので、辞書型とします。
# 手を認識できなくなるとエラー終了してしまうので、捉えているか判定する
if detection_result.hand_world_landmarks:
hand_landmarks_list = detection_result.hand_world_landmarks
handedness_list = detection_result.handedness
hand_world_landmarksで、ワールド座標と取るようにします。
if handedness[0].category_name == "Right":
・・・
elif handedness[0].category_name == "Left":
右手か左手かを判別し、データ格納先を振り分けます。
手のランドマーク情報のデータ構造はこのページの一番下に書かれているのですが、ちょっとわかりにくいですね😂
right_hand_data = []
for landmark in hand_landmarks:
right_hand_data_xyz = []
right_hand_data_xyz.append(landmark.x)
right_hand_data_xyz.append(landmark.y)
right_hand_data_xyz.append(landmark.z)
right_hand_data.append(right_hand_data_xyz)
・・・
left_hand_data = []
for landmark in hand_landmarks:
left_hand_data_xyz = []
left_hand_data_xyz.append(landmark.x)
left_hand_data_xyz.append(landmark.y)
left_hand_data_xyz.append(landmark.z)
left_hand_data.append(left_hand_data_xyz)
list型のright_hand_data_xyzに座標3点を格納し、それを一塊としてlist型のright_hand_dataに加えます。
座標は以下の並びになっているようなので、データの並びもこの前提とします。
出典:https://github.com/google-ai-edge/mediapipe/blob/master/docs/solutions/hands.md
right_hand_json_tmp['hand_right'] = right_hand_data # キー'hand_right'に配列right_hand_dataを割り当て jsonへの変換準備完了
right_hand_json = json.dumps(right_hand_json_tmp) #jsonデータに変換する
・・・
left_hand_json_tmp['hand_left'] = left_hand_data # キー'hand_left'に配列left_hand_dataを割り当て jsonへの変換準備完了
left_hand_json = json.dumps(left_hand_json_tmp) #jsonデータに変換する
辞書型の変数のキーに対して、list型のデータを格納します。
キーを設定するのは、UDP受信側で何のデータなのかを判別するためです。
json_dumps()で、辞書型をJSON形式に変換できます。
JSONとは
JavaScript Object Notationの略。
JavaScriptでのオブジェクトの書き方を参考に作られたデータフォーマットです。
キーと値をコロン記号で区切って表現します。単純なテキストデータであるため、処理が軽く、ソースコード上でも扱いやすいのが特徴です。
{"キー":値}
例) {"eight" : 8}
複数の要素がある場合、カンマで区切ることができます。
{
"eight" : 8,
"nine" : 9,
"ten" : 10
}
さらに、値としてJSON形式を入れ子にすることもできます。
{
"eight" : {
"nine" : 9,
"ten" : 10
}
}
さいごに
UDP送信そのものは簡単でした。
顔の送信データには座標を含めていないので、このままだと顔の傾きや回転を表現できません。
次回以降、Unity側がそれなりに動くようになったら調整します。
eightはJSONや辞書型に馴染みがなく、扱い方を探るのが今回最も苦労しました😇
今回の実装で何となくわかってきたので、結果的にはやってよかったです。
次回、Unity側のUDP受信を実装していきます。
それでは、今回はここまで。
ありがとうございました😊
コメント