はじめに
前回、MediaPipeで顔と手のトラッキングを試してみました。
まだ他の機能もあるようなので、どんなものなのか、やってみようと思います。
MediaPipeの機能
Face Detection
画像内の、顔のパーツの位置を点で表します。
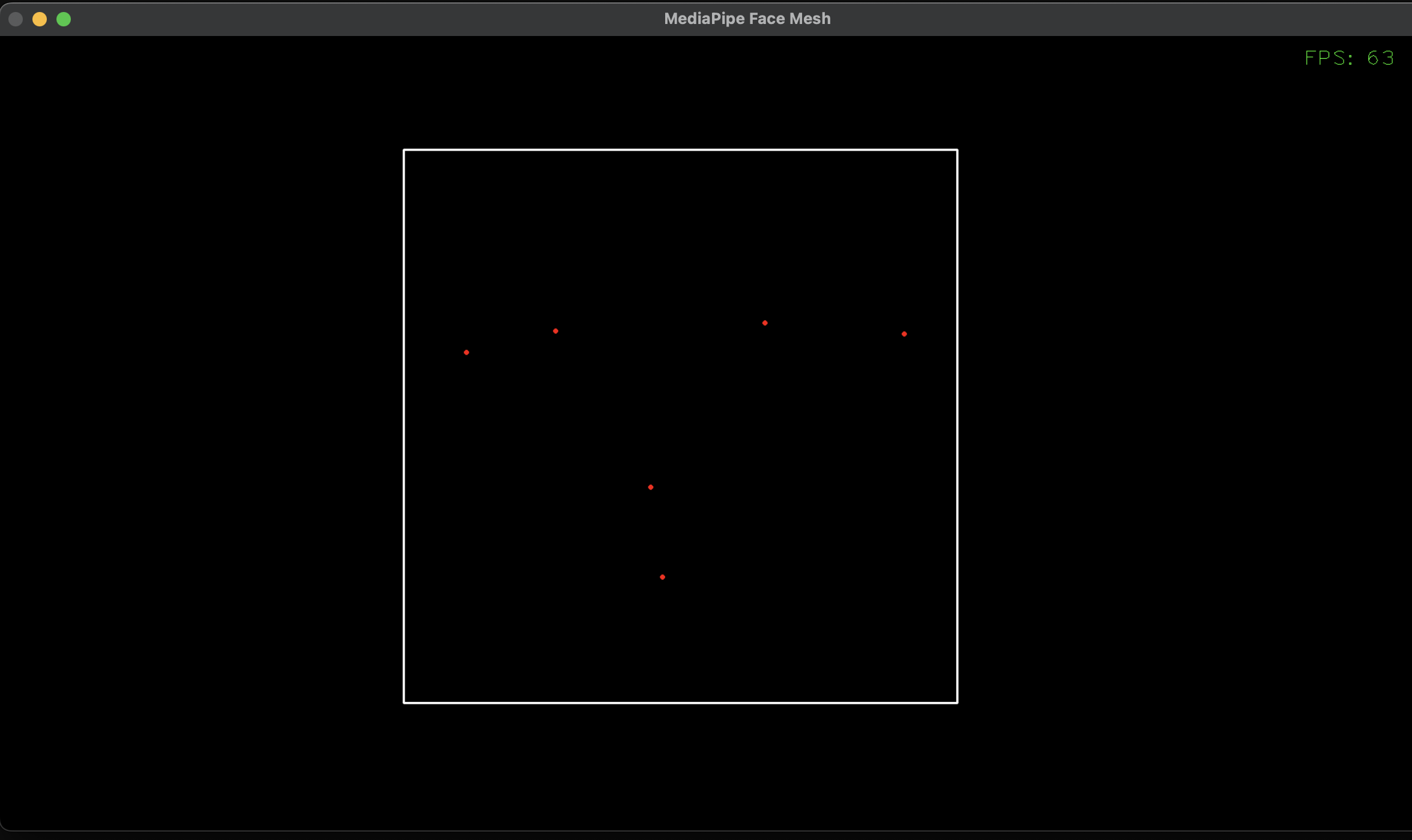
画像はわかりにくいのですが、白四角の枠と、赤い点が6つあります。
白四角は輪郭全体、赤点は両目・両耳・鼻・口の位置です。
Face Detectionサンプルコード
import cv2
import mediapipe as mp
import numpy as np
# フェイストラッキング関数
def face_detection_exec(img, facedetection):
img.flags.writeable = False
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# ランドマーク検出
results = facedetection.process(img)
img.flags.writeable = True
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
# 背景を黒にして、ランドマーク画像だけ残す
img_h, img_w, _ = img.shape
blank = np.zeros((img_h, img_w, 3))
img = blank
if results.detections:
# 検出したランドマークを画像内に描画
for detection in results.detections:
mp_drawing.draw_detection(
img,
detection)
return img
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_facedetection = mp.solutions.face_detection
cap = cv2.VideoCapture(0) # カメラID 内蔵カメラはおそらく0
# min_detection_confidence = ランドマーク検出成功判定の閾値
facedetection = mp_facedetection.FaceDetection(
model_selection=0,
min_detection_confidence=0.5)
# カメラが有効の場合のみ処理する
while cap.isOpened():
# カメラから画像1枚取得
success, image_org = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
tick = cv2.getTickCount() # fps計算用
# ホリスティックトラッキング
# 元画像から顔の特徴点のみ抽出
image = face_detection_exec(image_org, facedetection)
# image = cv2.flip(image, 1) # ミラー反転する
# fps計算し、画像内に埋め込む
fps = cv2.getTickFrequency() / (cv2.getTickCount() - tick)
cv2.putText(
image,
"FPS: " + str(int(fps)),
(image.shape[1] - 150, 40), # 画面右上あたり
cv2.FONT_HERSHEY_PLAIN,
2, # 文字の大きさ
(0, 255, 0), # 文字色(緑)
)
# PC画面に画像表示
cv2.imshow('MediaPipe Face Mesh', image)
#終了判定 ESCで終了する
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
Face Mesh
顔を詳細に検出し、眉・目・口・輪郭を動きをトラッキングします。
FACEMESH_TESSELATIONでメッシュ表示すると、鼻も映りますね。
※眉や目は前髪で隠れやすく、隠れるとうまくトラッキングできないので注意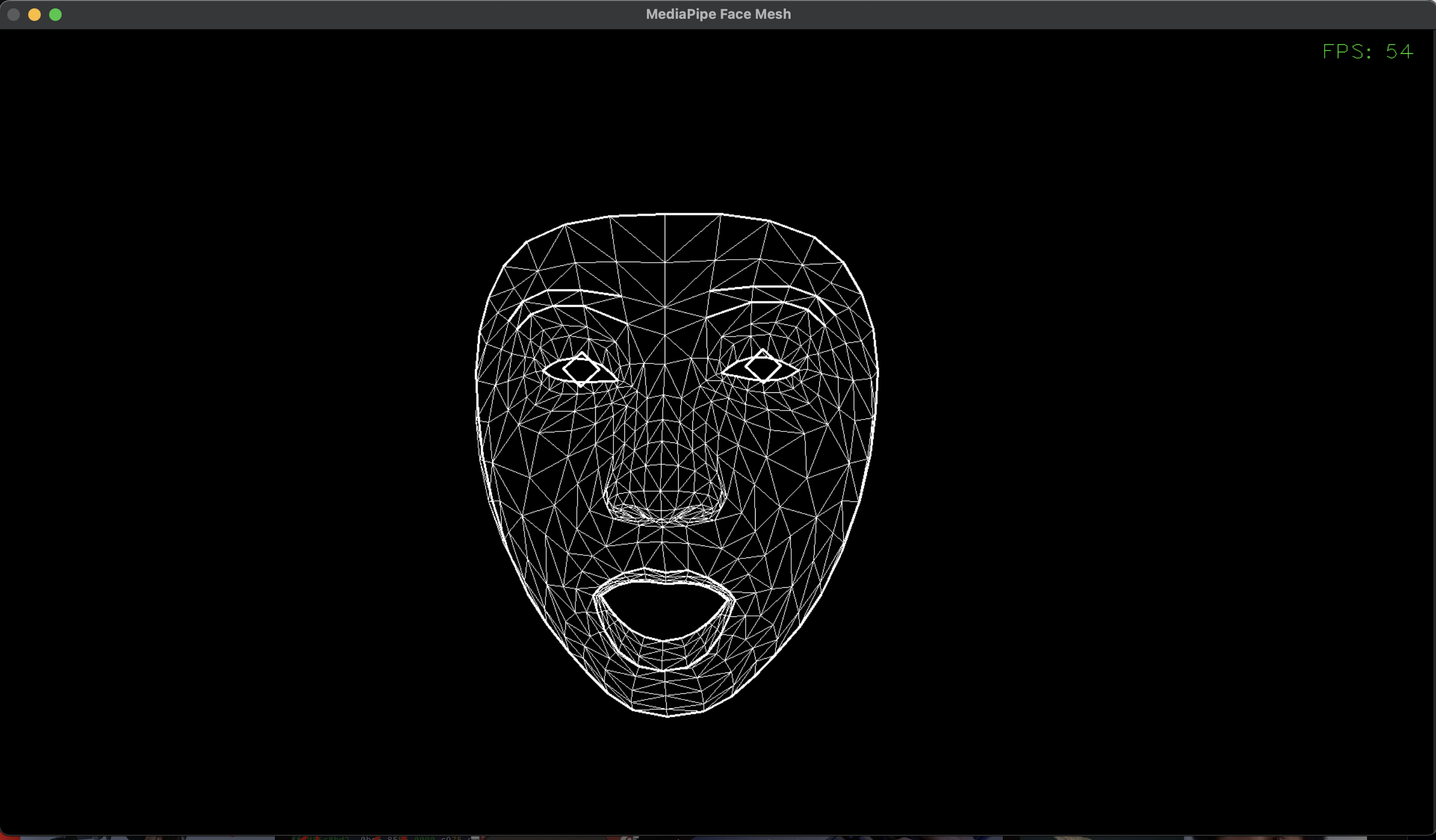
Face Meshサンプルコード
import cv2
import mediapipe as mp
import numpy as np
# フェイストラッキング関数
def face_mesh_exec(img, face_mesh):
img.flags.writeable = False
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 顔ランドマーク検出
results = face_mesh.process(img)
img.flags.writeable = True
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
# 背景を黒にして、ランドマーク画像だけ残す
img_h, img_w, _ = img.shape
blank = np.zeros((img_h, img_w, 3))
img = blank
if results.multi_face_landmarks:
# 検出したランドマークを画像内に描画
for face_landmarks in results.multi_face_landmarks:
# 顔の中をメッシュ表示する場合、このコメントアウトを解除する
mp_drawing.draw_landmarks(
image=img,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_TESSELATION,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_tesselation_style())
mp_drawing.draw_landmarks(
image=img,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_CONTOURS, # 目、口、輪郭の境界線
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_contours_style())
mp_drawing.draw_landmarks(
image=img,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_IRISES, # 虹彩
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_iris_connections_style())
return img
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_face_mesh = mp.solutions.face_mesh
cap = cv2.VideoCapture(0) # カメラID 内蔵カメラはおそらく0
# max_num_faces = 画像内で検出する顔の数
# refine_landmarks = 目の周りを細かくするか
# min_detection_confidence = ランドマーク検出成功判定の閾値
# min_tracking_confidence = ランドマークトラッキング成功判定の閾値
# static_image_mode = 静止画かどうか
face_mesh = mp_face_mesh.FaceMesh(
max_num_faces=1,
refine_landmarks=True,
min_detection_confidence=0.5,
min_tracking_confidence=0.5,
static_image_mode=False)
# カメラが有効の場合のみ処理する
while cap.isOpened():
# カメラから画像1枚取得
success, image_org = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
tick = cv2.getTickCount() # fps計算用
# フェイストラッキング
# 元画像から顔の特徴点のみ抽出
image = face_mesh_exec(image_org, face_mesh)
# image = cv2.flip(image, 1) # ミラー反転する
# fps計算し、画像内に埋め込む
fps = cv2.getTickFrequency() / (cv2.getTickCount() - tick)
cv2.putText(
image,
"FPS: " + str(int(fps)),
(image.shape[1] - 150, 40), # 画面右上あたり
cv2.FONT_HERSHEY_PLAIN,
2, # 文字の大きさ
(0, 255, 0), # 文字色(緑)
)
# PC画面に画像表示
cv2.imshow('MediaPipe Face Mesh', image)
#終了判定 ESCで終了する
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
Hands
手をトラッキングします。
顔のようなメッシュ表示はありませんが、指関節の細かな動きをとれます。
手を裏返す、手を握る、上下逆さにする、などしても、うまく追従できるようです。
ただ、手招きするような動作で、画面でみたとき手が平たくなるポイントがありますが、そのときはうまく追従できていませんでした。さすがに手の形から逸脱してしまうと、推論が難しくなるようです。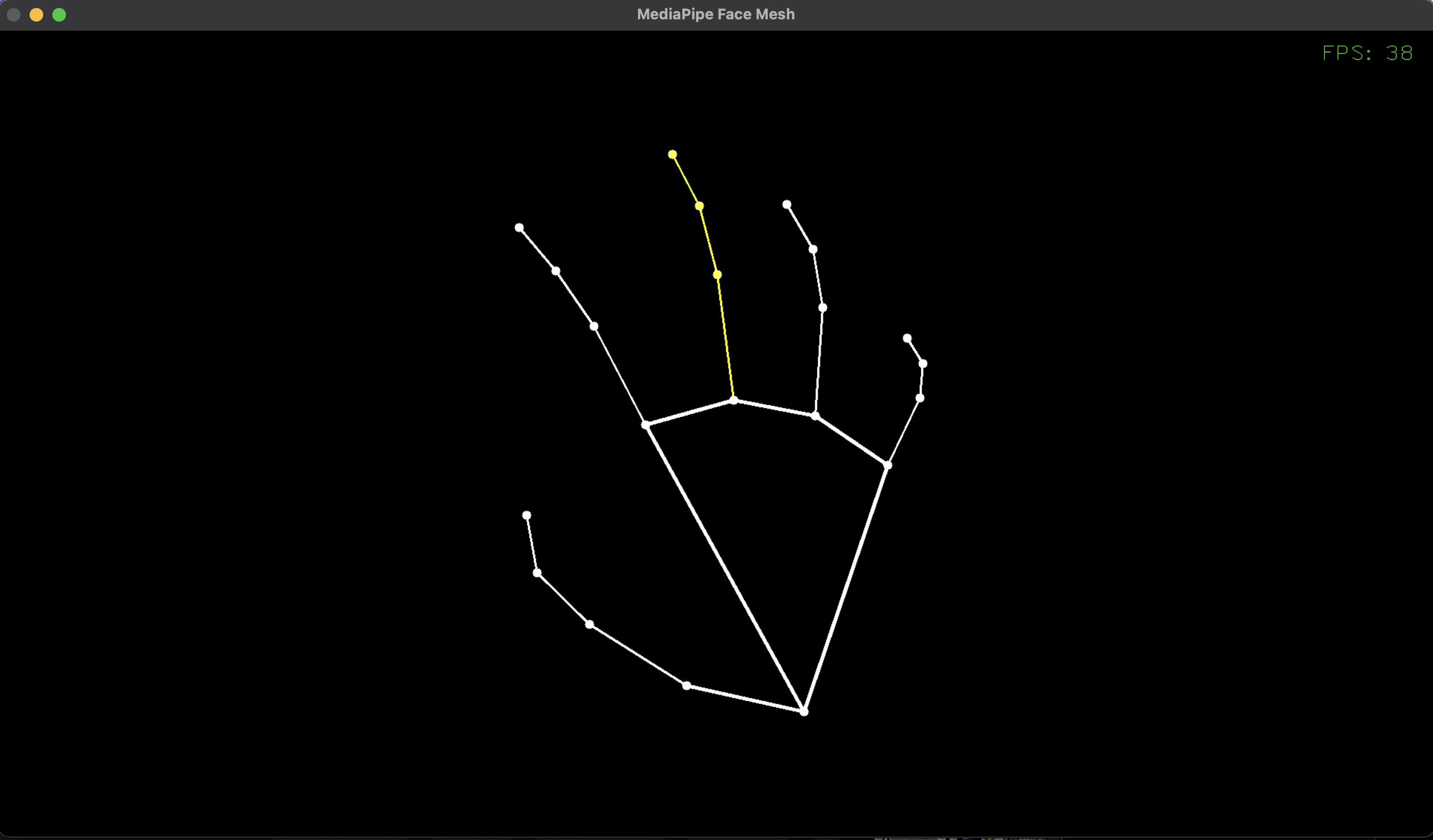
Handsサンプルコード
import cv2
import mediapipe as mp
import numpy as np
# ハンドトラッキング関数
def hands_exec(img, hands):
img.flags.writeable = False
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 手ランドマーク検出
results = hands.process(img)
img.flags.writeable = True
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
# 背景を黒にして、ランドマーク画像だけ残す
img_h, img_w, _ = img.shape
blank = np.zeros((img_h, img_w, 3))
img = blank
if results.multi_hand_landmarks:
# 検出したランドマークを画像内に描画
for hand_landmarks in results.multi_hand_landmarks:
mp_drawing.draw_landmarks(
image=img,
landmark_list=hand_landmarks,
connections=mp.solutions.hands.HAND_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_hand_landmarks_style(),
connection_drawing_spec=mp_drawing_styles.get_default_hand_connections_style())
return img
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_hands = mp.solutions.hands
cap = cv2.VideoCapture(0) # カメラID 内蔵カメラはおそらく0
# max_num_hands = 画像内で検出する手の数
# min_detection_confidence = ランドマーク検出成功判定の閾値
# min_tracking_confidence = ランドマークトラッキング成功判定の閾値
# static_image_mode = 静止画かどうか
hands = mp_hands.Hands(
max_num_hands=2,
min_detection_confidence=0.5,
min_tracking_confidence=0.5,
static_image_mode=False)
# カメラが有効の場合のみ処理する
while cap.isOpened():
# カメラから画像1枚取得
success, image_org = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
tick = cv2.getTickCount() # fps計算用
# ハンドトラッキング
# 元画像から手の特徴点のみ抽出
image = hands_exec(image_org, hands)
# image = cv2.flip(image, 1) # ミラー反転する
# fps計算し、画像内に埋め込む
fps = cv2.getTickFrequency() / (cv2.getTickCount() - tick)
cv2.putText(
image,
"FPS: " + str(int(fps)),
(image.shape[1] - 150, 40), # 画面右上あたり
cv2.FONT_HERSHEY_PLAIN,
2, # 文字の大きさ
(0, 255, 0), # 文字色(緑)
)
# PC画面に画像表示
cv2.imshow('MediaPipe Face Mesh', image)
#終了判定 ESCで終了する
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
Pose
顔から足まで、全身をトラッキングします。
顔や手の細かさは、やや簡素になります。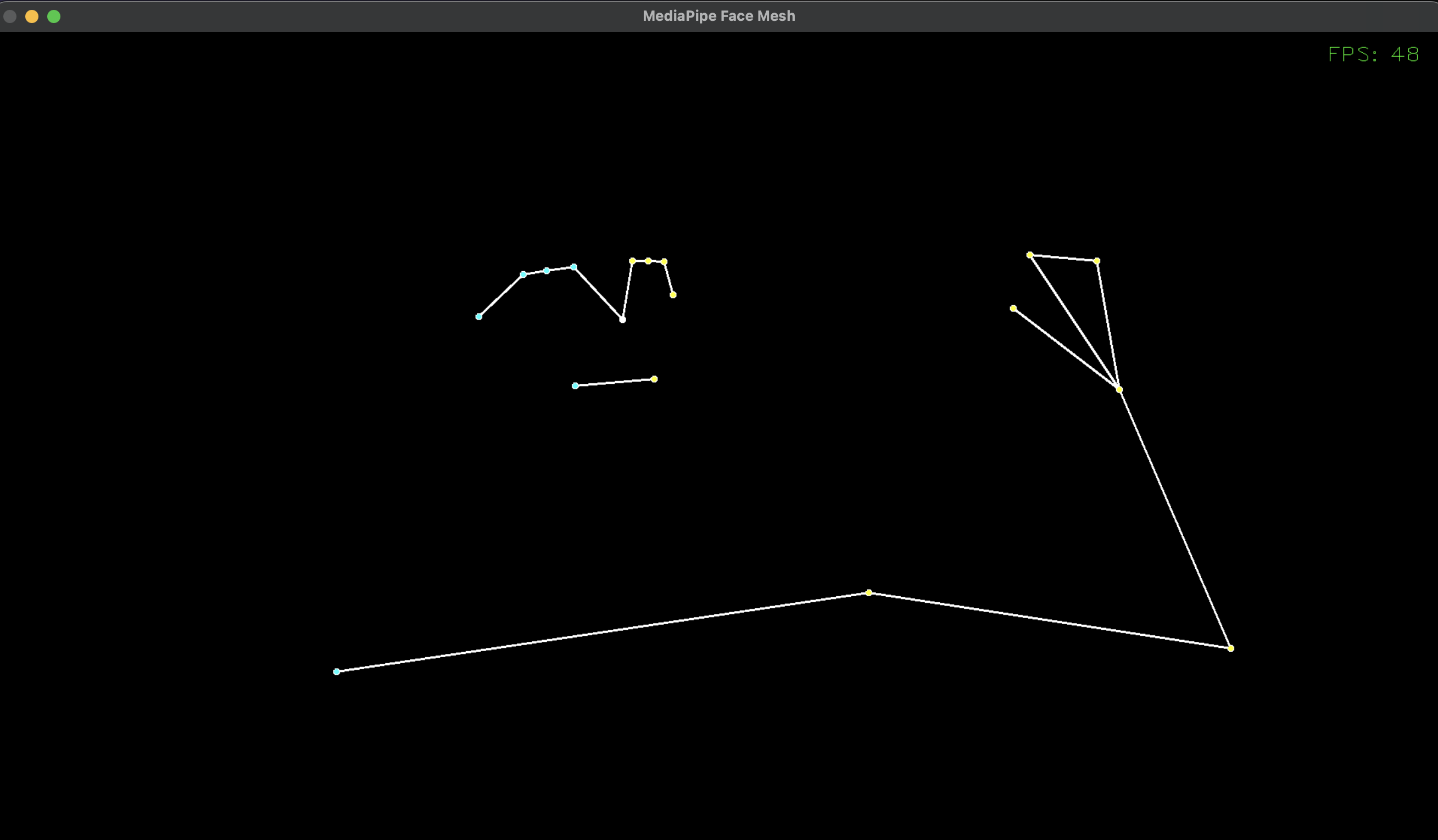
画像は肩から上と片腕を映しています。足まで映せば、ちゃんと追従します。
首は無いようですね。
顔は、目・鼻・口の位置だけになっています。
手は指4本が繋がって、ミトンを付けているような見た目になっています。指を曲げることはできません。
Poseサンプルコード
import cv2
import mediapipe as mp
import numpy as np
# ポーズトラッキング関数
def pose_exec(img, pose):
img.flags.writeable = False
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# ポーズランドマーク検出
results = pose.process(img)
img.flags.writeable = True
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
# 背景を黒にして、ランドマーク画像だけ残す
img_h, img_w, _ = img.shape
blank = np.zeros((img_h, img_w, 3))
img = blank
if results.pose_landmarks:
# 検出したランドマークを画像内に描画
mp_drawing.draw_landmarks(
image=img,
landmark_list=results.pose_landmarks,
connections=mp_pose.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style())
return img
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_pose = mp.solutions.pose
cap = cv2.VideoCapture(0) # カメラID 内蔵カメラはおそらく0
# min_detection_confidence = ランドマーク検出成功判定の閾値
# min_tracking_confidence = ランドマークトラッキング成功判定の閾値
# static_image_mode = 静止画かどうか
pose = mp_pose.Pose(
min_detection_confidence=0.5,
min_tracking_confidence=0.5,
static_image_mode=False)
# カメラが有効の場合のみ処理する
while cap.isOpened():
# カメラから画像1枚取得
success, image_org = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
tick = cv2.getTickCount() # fps計算用
# ハンドトラッキング
# 元画像から手の特徴点のみ抽出
image = pose_exec(image_org, pose)
# image = cv2.flip(image, 1) # ミラー反転する
# fps計算し、画像内に埋め込む
fps = cv2.getTickFrequency() / (cv2.getTickCount() - tick)
cv2.putText(
image,
"FPS: " + str(int(fps)),
(image.shape[1] - 150, 40), # 画面右上あたり
cv2.FONT_HERSHEY_PLAIN,
2, # 文字の大きさ
(0, 255, 0), # 文字色(緑)
)
# PC画面に画像表示
cv2.imshow('MediaPipe Face Mesh', image)
#終了判定 ESCで終了する
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
Holistic
顔・手・ポーズを総合的にトラッキングします。
Face Mesh・Hands・Poseを組み合わせたようなものです。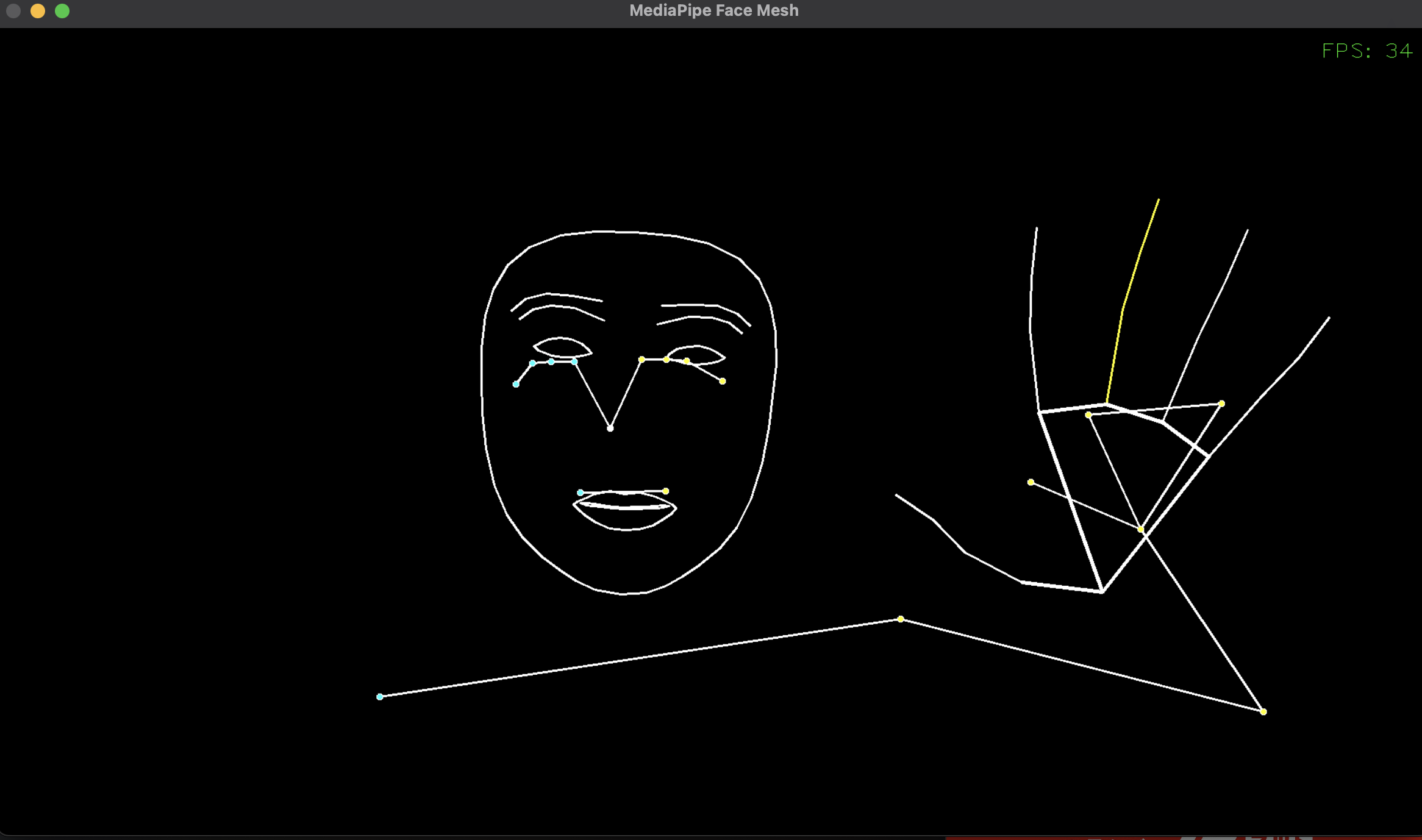
画像のときは全身映せませんでしたが、画角におさめればちゃんと追従します。
HolisticのFaceでは、瞳を検出することはできないようです。
また、上半身モードがあるらしい記事もあったのですが、eightの環境ではできませんでした🥺
顔はFace MeshとPoseが重なっています。
手はHansとPoseが重なっています。
この重なり、Poseのほうを非表示にしたいのですが、方法がわかりませんでした😭
Holisticサンプルコード
import cv2
import mediapipe as mp
import numpy as np
# 総合トラッキング関数
def holistic_exec(img, holistic):
img.flags.writeable = False
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# ランドマーク検出
results = holistic.process(img)
img.flags.writeable = True
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
# 背景を黒にして、ランドマーク画像だけ残す
img_h, img_w, _ = img.shape
blank = np.zeros((img_h, img_w, 3))
img = blank
if results.face_landmarks:
# 検出したランドマークを画像内に描画
mp_drawing.draw_landmarks(
image=img,
landmark_list=results.face_landmarks,
connections=mp_holistic.FACEMESH_CONTOURS,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_contours_style())
if results.right_hand_landmarks:
mp_drawing.draw_landmarks(
image=img,
landmark_list=results.right_hand_landmarks,
connections=mp_holistic.HAND_CONNECTIONS,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_hand_connections_style())
if results.left_hand_landmarks:
mp_drawing.draw_landmarks(
image=img,
landmark_list=results.left_hand_landmarks,
connections=mp_holistic.HAND_CONNECTIONS,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_hand_connections_style())
if results.pose_landmarks:
mp_drawing.draw_landmarks(
image=img,
landmark_list=results.pose_landmarks,
connections=mp_holistic.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles
.get_default_pose_landmarks_style())
return img
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_holistic = mp.solutions.holistic
cap = cv2.VideoCapture(0) # カメラID 内蔵カメラはおそらく0
# static_image_mode = 静止画かどうか
# min_detection_confidence = ランドマーク検出成功判定の閾値
# min_tracking_confidence = ランドマークトラッキング成功判定の閾値
holistic = mp_holistic.Holistic(
static_image_mode=False,
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
# カメラが有効の場合のみ処理する
while cap.isOpened():
# カメラから画像1枚取得
success, image_org = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
tick = cv2.getTickCount() # fps計算用
# ホリスティックトラッキング
# 元画像から顔の特徴点のみ抽出
image = holistic_exec(image_org, holistic)
# image = cv2.flip(image, 1) # ミラー反転する
# fps計算し、画像内に埋め込む
fps = cv2.getTickFrequency() / (cv2.getTickCount() - tick)
cv2.putText(
image,
"FPS: " + str(int(fps)),
(image.shape[1] - 150, 40), # 画面右上あたり
cv2.FONT_HERSHEY_PLAIN,
2, # 文字の大きさ
(0, 255, 0), # 文字色(緑)
)
# PC画面に画像表示
cv2.imshow('MediaPipe Face Mesh', image)
#終了判定 ESCで終了する
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
Segmentation
画像内の人物と背景を分離します。
Web会議のバーチャル背景のような処理ができます。
背景を緑、人物を青で塗りつぶしました。
Segmentationサンプルコード
import cv2
import mediapipe as mp
import numpy as np
# ポーズトラッキング関数
def selfie_segmentation_exec(img, selfie_segmentation):
fg_image = None
bg_image = None
img.flags.writeable = False
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 人物と背景を分離
results = selfie_segmentation.process(img)
img.flags.writeable = True
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
# 人物のマスク
fg_image = np.zeros(img.shape, dtype=np.uint8)
fg_image[:] = (255, 0, 0)
# 背景のマスク
bg_image = np.zeros(img.shape, dtype=np.uint8)
bg_image[:] = (0, 255, 0)
condition = np.stack((results.segmentation_mask,) * 3, axis=-1) > 0.1
# 第2引数が人物用、第3引数が背景用
img = np.where(condition, fg_image, bg_image)
return img
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_selfie_segmentation = mp.solutions.selfie_segmentation
cap = cv2.VideoCapture(0) # カメラID 内蔵カメラはおそらく0
# model_selection = 人物
selfie_segmentation = mp_selfie_segmentation.SelfieSegmentation(
model_selection=1)
# カメラが有効の場合のみ処理する
while cap.isOpened():
# カメラから画像1枚取得
success, image_org = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
tick = cv2.getTickCount() # fps計算用
# ハンドトラッキング
# 元画像から手の特徴点のみ抽出
image = selfie_segmentation_exec(image_org, selfie_segmentation)
# image = cv2.flip(image, 1) # ミラー反転する
# fps計算し、画像内に埋め込む
fps = cv2.getTickFrequency() / (cv2.getTickCount() - tick)
cv2.putText(
image,
"FPS: " + str(int(fps)),
(image.shape[1] - 150, 40), # 画面右上あたり
cv2.FONT_HERSHEY_PLAIN,
2, # 文字の大きさ
(0, 0, 255), # 文字色(赤)
)
# PC画面に画像表示
cv2.imshow('MediaPipe Face Mesh', image)
#終了判定 ESCで終了する
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
各機能のFPS比較
各機能において、ある条件下でどの程度のFPSが出るかを計測してみました。
検証環境:
PC:M4 Macbook Pro
Pythonバージョン:3.12.5
OpenCVバージョン:4.11.0
MediaPipeバージョン:0.10.21
計測条件:
顔 設定可能な場合は1つ
手 設定可能な場合は2つ
ミラー反転無し
結果:
| 機能名 | 平均FPS |
| Face Detection | 140 |
| Face Mesh (TESSELATIONあり) | 100 |
| Face Mesh (TESSELATIONなし) | 120 |
| Hands | 40 |
| Pose | 50 |
| Holistic | 35 |
| Segmentation | 47 |
補足
ミラー反転すると、FPSは落ちました。
検出対象物が画面外にあったり、隠れていた場合でも、FPSに影響ありませんでした。
Holisticでは顔+手+ポーズを検出していますが、どれか1つにした場合でもFPSに影響ありませんでした。
所感:
やはりと言うか、検出対象の数が多いほど負荷が高いことがわかりました。
特に、手があるかないかで大きく変わりますね。
Poseは全身をトラッキングしますが、それよりHandsのほうが負荷が高くなっています。Handsのほうが、手指の細かい動きまで捉える(検出対象物が多い)からだと考えられます。
Holisticでは顔や手の細かいトラッキングも可能ですが、全ての検出処理が行われるため、負荷が高くなります。なので、たとえば顔だけトラッキングしたい場合は、Face Meshを使用するほうが良いでしょう。
さいごに
アバターを作ろうとしたときには、総合的にはPoseで実装すると自由度が高そうです。
ただ、eightの場合は瞳のトラッキングもしたいのと、腕部や下半身のトラッキングは不要なので、Face MeshとHandsの組み合わせでやっていこうと思いました。
それでは、今回はここまで。
ありがとうございました😊

コメント